
Recently, I was exploring how to use AI models or LLMs in my laptop locally and that’s when I got to know about Ollama. It is one of the best and easiest ways to run open source AI models or LLMs locally in your machine.
Ollama was founded by Michael Chiang and Jeffrey Morgan, and as of September 2025, Jeffrey Morgan serves as the CEO of Ollama. The company has made it incredibly simple for anyone to run powerful AI models without needing any technical expertise or expensive cloud subscriptions.
Getting Started with Ollama
To get started, you just need to visit https://ollama.com/ and click on the download button. You will be taken to a page showing download options for various operating systems including macOS, Linux, and Windows. There will be a large download button as shown in the picture where you simply click on that button to start downloading Ollama.
The installation process is straightforward. Once downloaded, you will have to extract the zip file and then click on the Ollama application. Since I am using Mac, I went to downloads where the application’s icon is located, dragged it and dropped it in the Applications folder in Finder. For Windows users, the process is similar – you just run the installer and follow the simple setup wizard. For Windows installation help, you may use the video tutorials from TechWithTim where in one of his videos about ollama (click here for the video), he explains the process step by step.
Once that is done, Ollama is installed and you will find an Ollama app in your menu bar. While there’s a graphical interface available when you click on Ollama in the menubar, the better option is using the command line interface (CLI) where you will have full control over the AI models. The CLI gives you more flexibility and options to manage your models efficiently.
Choosing the Right Model
Now comes the exciting part – choosing which AI model to run. In the same link where you downloaded Ollama, you would find a search box with a placeholder ‘Search models’ as shown in the first picture. Here you can type any open source model name and it would show you all the available details.
The size of the model you choose depends on your RAM size, which is clearly shown when you search for models. For example, when I typed “qwen3” I found the Qwen3 model hyperlink, and when I clicked on that, I found the details of all available Qwen3 models with their sizes and system requirements as shown in the below picture.
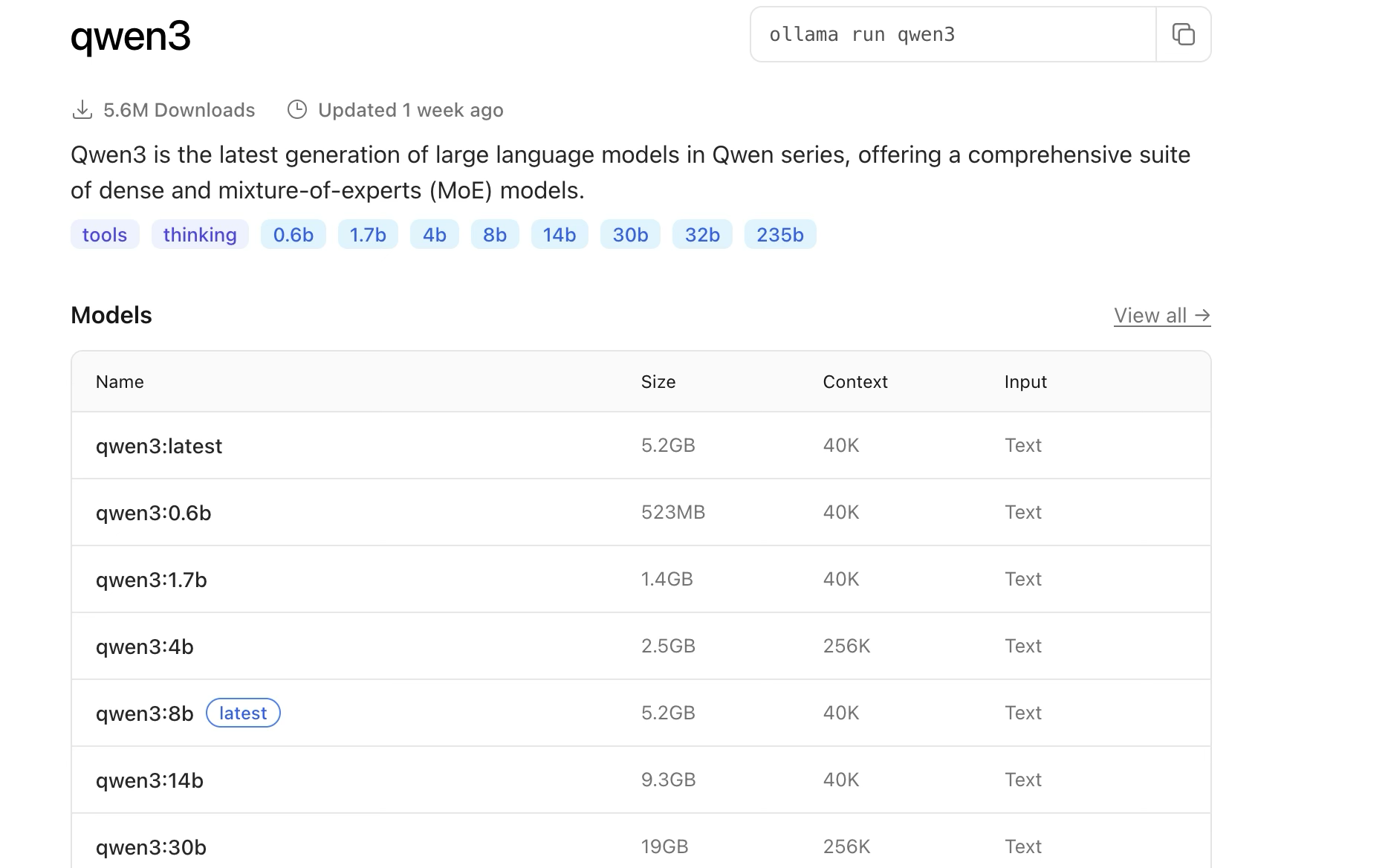
Since my RAM is 16GB, I would go for a smaller model which can smoothly run on my machine. The general rule is simple:
- 4GB RAM: Try 1B parameter or lower parameter models
- 8GB RAM: Try 3B parameter or lower parameter models
- 16GB RAM: Try 7B parameter or lower parameter models
- 32GB+ RAM: Try 14b parameter or lower parameter models
For my setup, I clicked on “qwen3:1.7b” and its details became visible. On the right side, you would find a command like ‘ollama run qwen3:1.7b’ along with a copy icon. You just need to click on that icon and the command will be copied to your clipboard.
Running Your First Model
Before we proceed to run a model, open your terminal or command prompt. Now paste the command you copied earlier. In my case, it was “ollama run qwen3:1.7b”. When you run this command for the first time, Ollama will automatically download the model files, which might take a few minutes depending on your internet speed and the model size.
After the download is complete, you will be able to see something like the image shown below, and then you can start chatting with your model just like ChatGPT, but with the huge advantage of having it run locally on your machine without any privacy concerns.

The Latest Models – Qwen3
What’s exciting is that Ollama now supports the latest AI models. For instance, Qwen3, which was released in April 2025, is the most recent version from Alibaba’s Qwen team. This is a significant upgrade from the previous Qwen2.5 that came out in September 2024.
Qwen3 comes in various sizes:
- Qwen3-0.6B (perfect for low-end machines)
- Qwen3-1.7B (good balance for 8GB RAM)
- Qwen3-4B (great for 16GB RAM)
- And larger versions for high-end setups
The latest Qwen3 models have a unique feature called “Thinking” mode and “Non-Thinking” mode that let you control how much the model reasons through problems, giving you flexibility between speed and accuracy.
Hugging Face Integration
Initially, I thought there was a limitation in Ollama as I could not find some of the latest models which are available on Huggingface. Let me give you some introduction to Hugging Face – it can be called the GitHub of AI. It’s where researchers and developers share their AI models, datasets, and tools.
But here’s the amazing part – Ollama is such a powerful tool that you can run even Hugging Face models directly! You just need to follow a simple command format like ollama run (the hf model name) as provided in the code below which will automatically pull and load the model from Hugging Face for use. This opens up thousands of additional models that you can try locally.
ollama run hf.co/Qwen/Qwen3-0.6B-GGUFcopy and paste this command in your terminal to download a model from huggingface in ollama
Advantages and Disadvantages
Advantages:
- Complete privacy – your conversations never leave your machine
- No internet required once models are downloaded
- No subscription fees or usage limits
- Fast responses (depending on your hardware)
- Access to cutting-edge open source models
Disadvantages:
- Model performance depends on your RAM and CPU
- Larger, more capable models need more powerful hardware
- Initial model downloads can be large (several gigabytes)
- Smaller models may not be as accurate as cloud-based solutions like ChatGPT
However, you can improve the performance of smaller models by fine-tuning them for your specific use cases, which I may discuss in my next blogs. If you are interested in learning how to fine tune a small model, please let me know the same in comments section.
Getting Help and Next Steps
If you run into any issues, the Ollama community is very helpful. You can find troubleshooting guides on their official website, and there are active discussions on GitHub and Reddit where users share tips and solutions.
For your first experience, I recommend starting with a 4B parameter model or lower if you have 16GB RAM, or a 1B model or lower if you have 8GB RAM. These provide a good balance between capability and performance.
Please do let me know in the comments section if you wish to learn about fine tuning a small model for specific tasks and how to set up more advanced configurations. Until then, happy experimenting with your local AI setup!


Pingback: How to Set Up Local AI-Powered Code Completion in VSCode